
 Last modified:
Friday, 09-Oct-2020 00:59:30 UTC. Maintained by: Elisa E. Beshero-Bondar
(eeb4 at psu.edu). Powered by firebellies. Last modified:
Friday, 09-Oct-2020 00:59:30 UTC. Maintained by: Elisa E. Beshero-Bondar
(eeb4 at psu.edu). Powered by firebellies.
Last modified:
Friday, 09-Oct-2020 00:59:30 UTC. Maintained by: Elisa E. Beshero-Bondar
(eeb4 at psu.edu). Powered by firebellies. Last modified:
Friday, 09-Oct-2020 00:59:30 UTC. Maintained by: Elisa E. Beshero-Bondar
(eeb4 at psu.edu). Powered by firebellies.XSLT is designed to transform XML into other kinds of XML, including HTML. First designed in 1999, it co-evolved with XPath, with working groups at the W3 Consortium collaborating on both. By 2007, both XPath and XSLT were well integrated together, which made XSLT a very powerful transformation language, capable of executing very precise manipulations and functions in remixing XML documents. That is really what XSLT is for: It is called a stylesheet language, which might remind you of CSS (Cascading Stylesheets), although CSS is very limited by comparison with XSLT. CSS cannot change the order of elements or the content of a document, but instead simply styles the elements already in place, as its functions are limited to presentation and display. XSLT, by contrast, can generate new kinds of documents from a base XML file, and was designed to translate one form of XML into another form (as, for example: XML to XHTML, TEI to XHTML, XML to SVG (scalable vector graphics, a form of XML that plots lines and shapes), or XML to KML (or Keyhole Markup Language, a form of XML designed for plotting placemarks and routes on Google Earth and other map interfaces.
XSLT is a kind of XML document, with a single root element, <xsl:stylesheet> that contains some very important attributes that define what the XSLT is transforming, from what and into what. Following that is an <xsl:output> statement that sets rules for the output document. Then the rest of the document is typically a series of <xsl:template> rules, which are written to match on particular elements of the input document. The way XSLT does this is different from most programming languages, which describe a set order or procedure. By contrast, XSLT is a declarative language, which means that its template rules declare what to do in the event a particular element shows up in the document: The rules seek to match specific scenarios: If there is a <name> element, and a template rule to match, <template match="name">, the rule will “fire” and generate output according to scenario you have written in the template. (So, for example, you might write a template rule that matches on all <name> elements in an XML file, and outputs them all in an HTML list. Inside an <xsl:template> is typically an <xsl:apply-templates> rule which effectively calls on one or more of the elements in a file to be match the next appropriate template for them.
To get started writing an XSLT file in <oXygen/> go to File→New Document, and choose XSLT. Typically we write and run XSLT in oXygen using the “XSLT debugger” view, which we show you in the graphic below. In that view, we choose an input file and an XSLT file to run, select a kind of output, and produce it in the output window on the right:
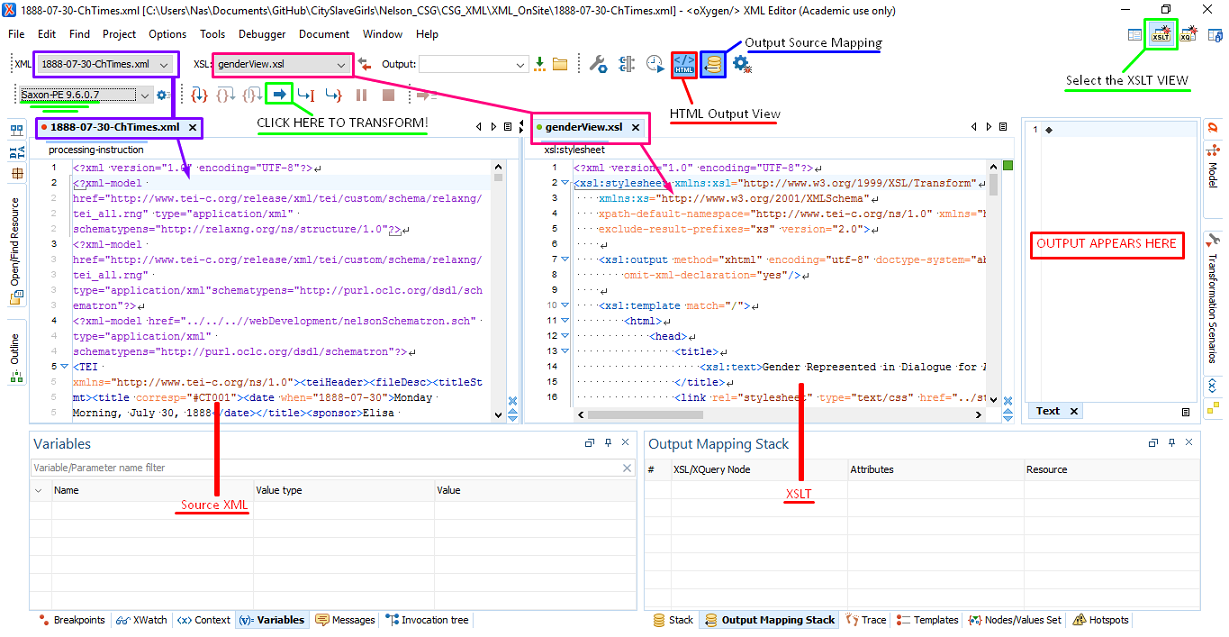
You don’t have to write any rules at all in XSLT. You could simply write a stylesheet with no template rules, and it would output all of the plain text of your document. That’s because XSLT has built-in rules that by default with output text nodes of all elements. The built-in rules start at the root of the element, and unless they are told to stop or diverted by template rules they will walk the whole XML tree and output any text they find.
If you open an XSLT stylesheet in <oXygen/>, as of 2016 you will see this opening and root element. We will usually need to alter this a little:
The part of this we need to alter are the @xmlns attributes, usually to add something more. These are the namespace declarations, which indicate the namespaces of the file from which we are reading (our input XML document), and the output we are writing to (XML or HTML, etc). When things go very badly wrong in XSLT and no output is generated at all, it is nearly always a namespace issue: you may have forgotten to include the appropriate namespaces! For example, in our work on the Digital Mitford project, and in some of your homework exercises, you will need to be reading from the TEI namespace and be outputting to XHTML: To do that you must add the appropriate attributes to the <xsl:stylesheet>, indicating that TEI is the default XPath namespace and that the XHTML namespace applies as well. Here is our series of declarations that we would use to read from an input TEI XML document and output HTML 5:
Of course we don’t bother to memorize this, and typically copy and paste the namespace values from one file to the next (or by consulting pages like this one)!
We need to write another “top-level” statement (an immediate child of the root element) that indicates the kind of output the XSLT file is generating. (This is necessary to output a valid HTML 5 document written in XML syntax.) The <xsl:output/> element is self-closing, and its first attribute, @method needs to designate one of the following options as its value: "xml" (which is the default), "xhtml", "html", and "text".
We set "xhtml" here when outputting HTML 5 to avoid validation errors in our output. There are other attributes to place on the output statement, which we’ll explain by walking through this example:
The method is set to xhtml to control the xml syntax of the output document (as HTML in XML form). We set @encoding to utf-8,
because it’s the universal
Unicode character set, the most widely compatible character set for use on
the World Wide Web. The @doctype-system, must be set to generate an HTML 5 doctype declaration in your output.
Lastly we set @omit-xml-declaration to "yes" to suppress the xml line at the top of the output HTML (The precise setting of the @doctype-system attribute is, as of February
2016, the easiest way in XSLT to generate the current doctype statement for HTML 5,
and the “about:legacy-compat” part of it is actually for compatibility with software
that outputs HTML rather than compatibility with browsers.).
The last top-level elements we need to tell you about are for controlling white space in your output. These are optional, but occasionally really necessary depending on the output you need and the state of your source file:
Use xsl:strip-space to remove white space inside the
elements in the list. Notice that the attribute (@elements) takes a space-delimited list of element names. The idea is that
you may need to remove extra spaces in the text of some of your elements, such
as
new-line characters and indentations at beginnings of lines, so you use strip-space
to systematically remove them all. By contrast, you’d use xsl:preserve-space to keep the white space.
Usually we don’t need these elements, but when you need them you will know, because your output will have too much white space, or your formatting will be all wrong.
The main part of the XSLT stylesheet are its template rules. When you write an xsl:template, you specify an @match attribute which calls out to particular elements. The value of
@match can be described as XPath-like
or an XPath pattern
: This is because we do not designate the
template @match to walk down the XML document tree. No.
Instead, the elements come to the template rule, and if you were to write a
full XPath expression with the leading // to designate walking down from the root,
that would have no effect. With xsl:template rules, the elements in the input XML
are matched out of context with their hierarchy. For example, if you have written a
template match for <xsl:template match="div">, that
rule is going to “fire” any time a div comes
by from the source document.
That can be really useful if we want a template rule to match all the divs in the hierarchy and treat them the same way. But usually that is not what we want. This is where the “XPath-like” or XPath-pattern syntax comes in: In a file with a complex hierarchy, like one of our Pacific Voyage Narratives, you may want to process Book (<div> elements directly under the <body>) differently from Chapter (<div> elements directly under Books), and so, using XPath-like syntax for @match, you can write one template rule for match="body/div" and another for match="div/div". You can also use predicates; for example, to process only the date elements for the year 1769, you can write a rule for xsl:template match="date[contains(., '1769')]". Those template rules will only match on the special cases you designate as they come up, wherever they come up in the document.
To write a complete template rule, you first have to call for a particular kind of node in your document (usually an element, but maybe other things), and then you have to do some action with it. The action usually creates output nodes, and then goes on to apply templates to the children of the current context node that has come by. So, to output lines of poetry in the form of HTML paragraphs so you can preserve the line breaks, you could write the following template rule:
Here is what happens when this rule fires: A <line> element drifts by this template rule and is caught by the @match attribute. The template takes its contents (basically consumes the node), and in its place it outputs an HTML <p>. What’s inside that <p> element generates its contents: <xsl:apply-templates/> by itself with no attributes says, process the contents (the text contents) of this element it is consuming. <xsl:apply-templates/> will process the contents of <line> and pass its child nodes on to the templates that apply to them.
You might want to process something in particular in a template rule, to direct <xsl:apply-templates/> to a next element that you want to be consumed in this particular position: perhaps something specific you would want to see next within the HTML element you are constructing, to restrict what comes next. For example, say you are working with our Georg Forster Pacific Voyage text coded in TEI, and you do not want to output the entire document. Say you only want to output a pair of nested HTML lists: Inside an outer list, we want to generate the chapter headings in the Forster file, and inside each chapter list entry, we want to make an inside list of each of the place names we have tagged inside that chapter (not worrying for the moment about whether those place names are repeated in the chapter). We will do this with an HTML unordered list (coded with an outer ul and an inner series of li (list items), with an outer list containing the Chapter headings and an inner list for each chapter holding the <placeName> elements within it. For this transformation from TEI we are going to need three template rules, to sit at different levels of our stylesheet. Here’s how we wrote it:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
exclude-result-prefixes="xs"
xmlns="http://www.w3.org/1999/xhtml" version="3.0"
xpath-default-namespace="http://www.tei-c.org/ns/1.0">
<xsl:output method="xml" omit-xml-declaration="yes" doctype-system="about:legacy-compat"/>
<xsl:template match="/">
<html>
<head>
<title>Places Mentioned in Georg Forster Account</title>
</head>
<body>
<h1>Places Listed in Each Chapter of Georg Forster’s Voyage Record</h1>
<ul>
<xsl:apply-templates select="//text/body//div[@type='chapter']"/>
</ul>
</body>
</html>
</xsl:template>
<xsl:template match="div[@type='chapter']">
<li>
<xsl:apply-templates select="head/l"/>
<ul>
<xsl:apply-templates select="descendant::p/placeName"/>
<!--ebb: In this stylesheet, we wanted to include only the placeName elements inside the body paragraphs of the chapters.
So we set our @select statement to step down and collect only these placeNames -->
</ul>
</li>
</xsl:template>
<xsl:template match="p/placeName">
<!--ebb: This template rule matches on a pattern:
Any time this rule is called, it finds a placeName that is the child of a body paragraph.
In the previous template rule, we called for this template to be applied *only selectively*
that is, *only to the placeNames inside the paragraphs within chapter div elements.*
So this template rule will only fire under those selective conditions. -->
<li><xsl:apply-templates/>
<!--ebb: When we don't use an @select on apply-templates, we simply pass the contents of the current element being processed on to whatever template rules
in the document are ready to process it, and if there is only plain text inside, plain text will be output.
Try copying and pasting this XSLT into oXygen, run it over the Georg Forster file, and study the output HTML.
As you’ll see from the output, perhaps we should consider modifying this rule!
We seem to be outputting note elements that are children of placeName in this document, which introduces some clutter to our output results!
Sometimes running a transformation can show us some things we may want to change about our source code,
or things we can try to exclude or modify in our XSLT transformation. -->
</li>
</xsl:template>
</xsl:stylesheet>
In the stylesheet above, the very first template rule matches on "/", and that indicates the XML root element. When we transform XML to HTML we begin with this
template match on root, so that we say the basic structural elements of the XML file are to be replaced by the basic structural elements of an HTML document.
We begin basically writing the document hierarchy of an HTML page, from its <html> document node (or root) onward, any outer level element that we expect to appear only once in the document hierarchy.
So up here in the template rule matching on the document node, we plot out the basic structural units of the HTML file and we set up the outer element that creates any unordered list or table we need.
Where we need to reach in and grab more deeply nested, repeating elements in the hierarchy, we need to invoke and fire new template rules, via xsl:apply-templates,
which we can specify as needed with the @select attribute to direct which parts of the XML file will be consumed and processed in particular lists or positions in the output HTML document. Notice that the @select attribute on xsl:apply-templates is a literal XPath expression. In the template rule matching div @type="chapter" we see two ways of stepping down into a literal XPath from the current context node,
whatever it is: In the first xsl:apply-templates @select, we step into a child node and then down another path step to the <l> (or line) element that is the child of head:
head/l. In the second xsl:apply-templates @select, we reach down the descendant:: axis from the current template match (or context node) to select a specific node to process next. We could also have written that xsl:apply-templates @select like this:
Here we used the dot
notation to indicate the current context node. This dot
notation, ., is very important
because when there is nothing indicated to the left of it our // descendent axis notation (or a / child axis notation) would otherwise be read as starting from the root of the XML tree and heading all the way down, rather than reading within a specific chapter and looking all the way down through its children and children ’s children only within the chapter. This is because xsl:apply-templates @select is a literal XPath expression that must be defined in terms of the current context node, quite unlike what we described with the XPath-like
syntax in the template’s @match. Notice that we only need to use the dot notation when we are designating the descendant axis with its abbreviated double-slash form from the current context node . We do not use it here to step down to the immediate child or over to an attribute on the current context node: we can simply designate those by element name or by @attribute and no slash is necessary (so therefore no dot notation is necessary either). So that is why we wrote: <xsl:apply-templates select="head/l"/> in the first template rule above; but we wrote <xsl:apply-templates select="descendant::p/placeName"/> in the same rule, in order to step down the descendant axis from the context node. After all, we do not need to use the dot if we always specify the axis name at the start of the @select value, and we think it is best practice always to specify the axis direction here.
If we wanted to calculate a count() or take the distinct-values() of a series of output elements, or calculate and output string-length() of a node, or otherwise execute XPath functions, we would write something like this: <xsl:value-of select="count(placeName)"/>, to deliver the calculated value of something. We would use this in place of our usual <xsl:apply-templates/>
One way not to output anything for an element is to write an empty template rule for it! For example, you could ensure that none of your paragraphs were ever output if you wrote the following:
This works to suppress the built-in rule to output text when no rules are defined, and effectively suppresses your paragraphs.
Use @match only when we’re defining a template rule.
We use @select in the internal part, on one of two XSLT elements: <xsl:apply-templates/> or <xsl:value-of/>.
We don’t have to use @select at all! We could simply go with <xsl:apply-templates/> if we want to duplicate ALL the contents of the thing we’ve matched in this place. We use @select when we need to be selective about what we’re going to process at the points of our match. So, let’s think about this with a couple of examples, one that uses <xsl:apply-templates/> with NO @select attribute, and one that uses @select.
Example 1: simple <xsl:apply-templates/> (no @select):
This template rule makes an @match on something "XPath-like": We use XPath syntax to define it, but notice that it is NOT a full XPath expression, because we can’t see where it originates: we haven’t defined a path down to it from the root element. But what we’re doing is looking for a pattern, wherever it turns up in the XML tree: wherever we see a div/div//head (or a head element that sits in a configuration like this), go match on it, whether it appears up near the root element, or down inside a body paragraph). When we are there, the rule says, output an <h1> HTML element (for a top-level heading in HTML), and inside output the full contents of our XML <head> element, and then go on and process any children of head by the other template rules I’ve written in this XSLT file: Apply templates from this point on down the XML tree.
vs.
Example 2: <xsl:apply-templates select=".//something"> using @select (when and why we do it):
This rule says, first of all, make a template @match on any placeName, wherever it appears in my XML input file. When you are there, <xsl:apply-templates select="@ref"> says, go and process selectively: We don’t want the whole output here: What we want is ONLY the contents of the @ref attribute sitting on <placeName ref="Someplace">text-content-here </placeName>. The template rule will go and read the contents of the @ref attribute and output it here in the transformed HTML, wrapped in a <strong> element to present it as bold. <xsl:apply-templates select="@ref"> also says "go and apply the other template rules on this sheet to any children of placeName (if there are any).
Think of @select this way:
Wherever our template rule has matched, the apply-templates @select expresses a definite XPath from that point—usually to a child element or to an attribute, or to some specific point that you want to process so that you don’t output the full content of the thing the template has matched on. Use @select when you want to define very specific output.
Please continue by reading and consulting the following pages on Obdurodon as you work on XSLT homework exercises. You will likely want to come back to review them later (as we do ourselves)!